Apple WatchでAmiVoiceの非同期APIを試してみた
 林政樹
林政樹

こんにちは。林です。
株式会社アドバンスト・メディアにて、iOS/WatchOSアプリの開発を担当しています。
はじめに
先日、弊社のAmiVocie Cloud Platform(以下、ACP)から非同期HTTP音声認識APIの利用が開始されました。これにより、ACPで利用できる音声認識APIは、以下の3つとなりました。
※各プロトコルの詳細については、下記の紹介記事をご参照ください。
前回は、ACPのWebSocket音声認識APIを利用して、リアルタイムで音声の文字化が可能なWatchOSアプリの開発に挑戦しました。
そこで今回は、新たに追加された非同期HTTP音声認識APIを利用して、
・ボイスメモのように音声を記録する
・記録した音声が非同期で文字化される
の2点の機能を持つWatchOSアプリを開発したいと思います。
興味のある方は、ぜひご一読お願いします。
アプリ
今回開発したアプリは、下図のように画面遷移します。

このアプリでは音声を録音し保存すると、記録画面には「...」の吹き出しが表示されます(このとき、音声が記録されたタイミングで、その音声はACP側に転送され、音声認識処理が実行されます)。
その後認識が完了したタイミングで、
・更新ボタンをタップ
・Apple Watchをバックグラウンドからフォアグラウンドに状態遷移させる
のいずれか行うことで、転送した音声の認識結果を取得し、「...」が認識結果に変更されます。
また音声記録は複数個記録することができ、各音声の認識結果は非同期的に反映されます(下図)。

実装
○開発環境
○ソースコード
○非同期HTTP音声認識API
冒頭でも述べましたが、今回は非同期HTTP音声認識APIを利用して、Apple Watchで記録した音声をバッチ認識させていきます。
そのためには、まず非同期HTTP音声認識APIの仕様を確認してみます。
I/F仕様 非同期HTTP音声認識API 詳細 - AmiVoice Cloud Platform を参照すると、アプリ側で非同期HTTP音声認識APIを利用するためには、
1. 音声認識ジョブを作成する
2. ポーリングをして音声認識ジョブの状態をチェックし、結果を取得する
の2つのステップを実行する必要があります。
具体的には、下図のようなApple Watch-ACP間でのやり取りが必要となります。
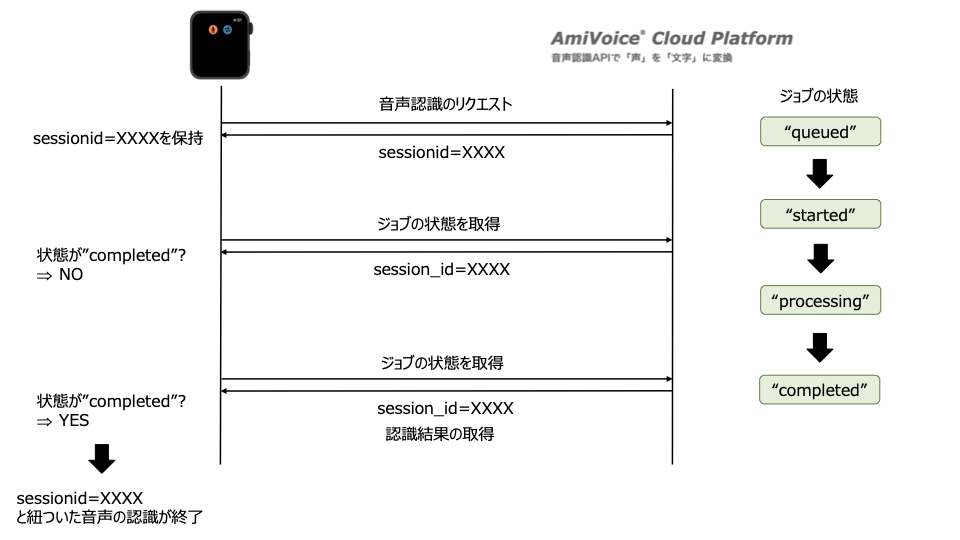
まず、ACP上で音声認識ジョブを作成するために、Watch側で音声ファイルをマルチパートPOSTすることで、音声認識のリクエストを行います。
作成された音声認識ジョブは、
・"queued"
・"started"
・"processing"
・"completed"
・"error"
の5つの状態を持っており(「I/F仕様 非同期HTTP音声認識API 詳細」- 「レスポンス」参照)、状態が"completed"になった後に、音声認識結果を取得することができます。
そのため音声認識ジョブを作成後は、このジョブの状態をポーリングにより都度監視する必要があります(但し、本アプリではユーザーの操作によってジョブの状態を監視しています)。
以上をまとめると、非同期HTTP音声認識APIを利用するためには、
②GETでジョブの状態を取得
の2つの処理をアプリ側で実装する必要があります。
本記事では、この①と②の実装についてご紹介していきたいと思います。
①POSTで音声認識のリクエスト
非同期HTTP音声認識APIを利用してバッチ認識を実行するための最初のステップである音声認識ジョブを作成するためには、該当する音声ファイルをマルチパート方式でPOSTすることで音声認識のリクエストを実行する必要があります。
「I/F仕様 HTTP音声認識API 詳細 - AmiVoice Cloud Platform」の「マルチパートPOSTのリクエストイメージ」を参照すると、WatchOSで音声認識のリクエストを行うために、下記形式に沿ってHTTPリクエストを作成していきます。
なお、今回の実装では
POST https://acp-api.amivoice.com/v1/recognize Content-Type: multipart/form-data;boundary=some-boundary-string-- some-boundary-stringsome-boundary-string Content-Disposition: form-data; name="u" (このパートには<AppKey> を格納します) -- some-boundary-string Content-Disposition: form-data; name="d" grammarFileNames=-a-general profileWords=hogehoge%20%E3%81%BB%E3%81%92%E3%81%BB%E3%81%92%E3%81%A6%E3%81%99%E3%81%A8 -- 音声データを Content-Disposition: form-data; name="a" Content-Type: application/octet-stream (最後のパートに some-boundary-string 格納します) -- --
上記のリクエストイメージを参考にして、SwiftでHTTPリクエストを実装すると、下記のようになります。ここでは、APPKEYと音声を格納する位置に注意していください。
let appKey = "XXXX...." // 自分のAPPKEY
let urlStr = "https://acp-api-async.amivoice.com/v1/recognitions" // 非同期HTTP音声認識APIのリクエスト先URL
guard let url = URL(string: urlStr) else { return }
var request = URLRequest(url: url)
request.httpMethod = "POST"
let boundary = String(arc4random() % 10000)
request.allHTTPHeaderFields = ["Content-Type":"multipart/form-data; boundary=\(boundary)"]
var body = Data()
body.append("--\(boundary)\r\n".data(using: .utf8)!)
body.append("Content-Disposition: form-data; name=\"u\"\r\n\r\n".data(using: .utf8)!)
body.append("\(appKey)\r\n".data(using: .utf8)!)
body.append("--\(boundary)\r\n".data(using: .utf8)!)
body.append("Content-Disposition: form-data; name=\"d\"\r\n\r\n".data(using: .utf8)!)
body.append("grammarFileNames=-a-general\r\n".data(using: .utf8)!)
body.append("--\(boundary)\r\n".data(using: .utf8)!)
body.append("Content-Disposition: form-data; name=\"a\"\r\n".data(using: .utf8)!)
body.append("Content-Type: application/octet-stream\r\n\r\n".data(using: .utf8)!)
// 音声データの格納
body.append(data)
body.append("\r\n".data(using: .utf8)!)
body.append("--\(boundary)\r\n".data(using: .utf8)!)
request.httpBody = body as Data
リクエスト作成後は、URLSessionのdataTask(with:completionHandler:)でリクエストを実行します。リクエストが完了後は、completionHandlerでレスポンス(Data, Error, URLResponse)が返ってきます。取得したデータは、JSONDecoderを介して任意のデータ型であるJobData型にデコードします。デコードに成功後は、job.sessionidといった形式でsessionidを取得することができます。
URLSession.shared.dataTask(with: request) { data, response, error in
if let error = error { return }
guard let data = data else { return }
do {
let decoder = JSONDecoder()
let job = try decoder.decode(JobData.self, from: data)
// -> jobからジョブの状態や認識結果を取り出す
} catch let error {
print("Error: \(error)")
}
}.resume()
struct JobData: Codable {
var sessionid: String?
var text: String?
}
②GETでジョブの状態の取得
非同期HTTP音声認識APIを利用するための次のステップとして、作成した音声認識ジョブの状態を確認し、認識結果を取得する必要があります。「I/F仕様 非同期HTTP音声認識API 詳細」の「2.ジョブの状態の確認、結果の取得」を見ると、
下記のように、音声認識ジョブの作成時に保持したsessionidをパラメータに設定し、GETを実行します。
GET https://acp-api-async.amivoice.com/v1/recognitions/{session_id}
またリクエスト作成時に、Authorizationヘッダーに自分のAPPKEYを指定します。
①の時と同様に、リクエストを実行するとcompletionHandlerでレスポンス(Data, Error, URLResponse)が返ってきます。取得したデータを、JSONDecoderを介してJobData型にデコードします。
let appKey = "XXXX...." // 自分のAppKey
let urlStr = "https://acp-api-async.amivoice.com/v1/recognitions/" + session_id
guard let url = URL(string: urlStr) else { return }
var request = URLRequest(url: url)
request.allHTTPHeaderFields = ["Authorization":"Bearer \(appKey)"]
URLSession.shared.dataTask(with: request) { data, response, error in
...
}.resume()
struct JobData: Codable {
// -> POST
var sessionid: String?
var text: String?
// -> GET
var audio_md5: String?
var audio_size: Int?
var session_id: String?
var service_id: String?
var status: String?
// -> If success
var utteranceid: String?
var code: String?
var message: String?
var results: JobResult?
// -> If failure
var error_message: String?
}
struct JobResult: Codable {
var text: String?
var results: [Results]?
struct Results: Codable {
var confidence: Double?
var starttime: Int?
var endtime: Int?
var rulename: String?
var tags: [Int]?
var text: String?
var tokens: [Tokens]?
struct Tokens: Codable {
var confidence: Double?
var spoken: String?
var written: String?
var starttime: Int?
var endtime: Int?
var label: String?
}
}
}
※ 2022/2/17 JobData構造体を一部修正
JobData型にデコードされたデータにおいて、job.statusの値を確認することで、ジョブの状態を把握することができます。
job.status == "completed"つまりジョブの状態が"completed"に遷移したとき、job.textより認識結果を取得することができます。取得した認識結果は、job.session_idと一致するアプリ側のsessionidと紐ついた「...」を認識結果に変更します。
このように、音声認識のジョブを作成した際に、それぞれのsessionidを保持していますので、複数個の音声ファイルをバッチ認識にかけても、各sessionidを頼りに認識結果を反映することができます。
以上より、
②GETでジョブの状態を取得
を実装することで、非同期HTTP音声認識APIを介したバッチ認識が可能となります。
今回開発したアプリは、こちらに置いてありますので、ご興味ある方はApple Watchで動作させてみてください。
おわりに
今回は、AmiVoice Cloud Platformの非同期HTTP音声認識APIを利用して、録音した音声をバッチ認識できるWatchOSアプリの開発をしてみました。実際に非同期HTTP音声認識APIを利用してみて、アプリに組み込みやすく、簡単に実装することができました。みなさんもぜひお試しください。
参考
AmiVoice Cloud Platform関連
マニュアル Archive - AmiVoice Cloud Platform
Codable, JSONDecoder
この記事を書いた人
-
林政樹
Swift/Objective-Cで、iOS/WatchOSアプリの開発をしています。