音声認識の仕組みをざっくり解説!

 大倉尭
大倉尭
皆さん、こんにちは!
弊社の音声認識技術を発信しているこのブログですが、実は肝心な「音声認識の仕組み」についての記事が今までありませんでした。
正直なところ、「音声認識の仕組み」をきちんと説明しようとすると本が1冊書けてしまうほどの分量があります。
そこで今回の記事では、ざっくりと、かつなるべく分かりやすく「音声認識の仕組み」を解説していきたいと思います。
目次
「音声認識」とは?
「音声認識」は一般に、音声をテキストにする技術のことをいいます。音声をテキストにするまでの流れは、下図のように大きく2つのステップに分かれます。
- 音声から特徴量を抽出する = 音響分析
- 特徴量を入力として、認識結果のテキストを得る = 認識デコーダ

では、このそれぞれの処理について見ていきましょう。
音響分析
例えば同じ「あ」という音であっても、音声の波形は話者の性別・年齢、録音するマイク等によって変わります。以下の画像は、私が「あ」と発話したものをノートパソコン内蔵のマイクとヘッドセットマイクでそれぞれ録音した際の波形を示したものです*1。

細かい部分を見ると、同じ「あ」でも波形に違いがあることがわかります。このため、音声波形のデータをそのまま認識デコーダに入力するのではなく、音響分析で音の特徴を数値化して、その数値(特徴量)を認識デコーダに入力しています。
具体的には、以下の手順で音響分析を行っています。
- 音声波形を細かく区切って切り出す(10ミリ秒単位など。10ミリ秒は1秒の100分の1です)
- 切り出された音声波形の区間それぞれ(弊社ではフレームと呼んでいます)に対しどの周波数の音がどれだけ強いかを調べ、数値化する
どの周波数の音がどれだけ強いかを計算したものをスペクトログラムと呼びます。以下の図をご覧ください。

先ほど示した2種類の「あ」と、ヘッドセットマイクで録音した「い」のスペクトログラムを可視化しました。スペクトログラムの横軸は時間、縦軸は周波数*2を表しています。色が明るいほどその周波数の音が強いということを表します。今回の音声は「あー」「いー」と伸ばして録音したため、時間によるスペクトログラムの変化はほとんどありません。
先ほど「同じ『あ』の音でも波形は異なる」という話をしましたが、スペクトログラムにすると明るい部分の位置が似ていることがわかります。また、「あ」と「い」では明るい部分の位置に差があることもわかります。周波数ごとの強さを分析することで、話者やマイク等によらない「あ」や「い」の音自体の特徴が見えてくるのです。
このスペクトログラムから特徴量(数値)を得る方法はいくつかありますが、複雑になるのでこの記事では省略します。興味のある方は「音声認識 特徴量」などのキーワードで検索してみてください。
認識デコーダ
音声から変換された特徴量は、認識デコーダに入力されます。認識デコーダには大きく分けて「DNN-HMMハイブリッド型(以下、ハイブリッド型)」「End-to-End型」の2つのタイプがあります。それぞれのタイプについて説明する前に、どちらのタイプでも使われるDNNについて説明します。
DNNとは
DNN(Deep Neural Network, ディープニューラルネットワーク)はその名の通り、「ディープ」な「ニューラルネットワーク」です。ニューラルネットワークは、生物の神経回路網を計算機上で模したものが始まりです。

上図の矢印一つ一つが「結合」にあたり、データによる学習で結合の強さを変化させます。左側のモデルで赤く囲った縦の○のひと固まりを「層(レイヤー)」といい、右側のモデルのようにこの層をたくさん重ねて(=ディープにして)複雑な処理を行えるようにしたネットワークをDNNと呼びます。
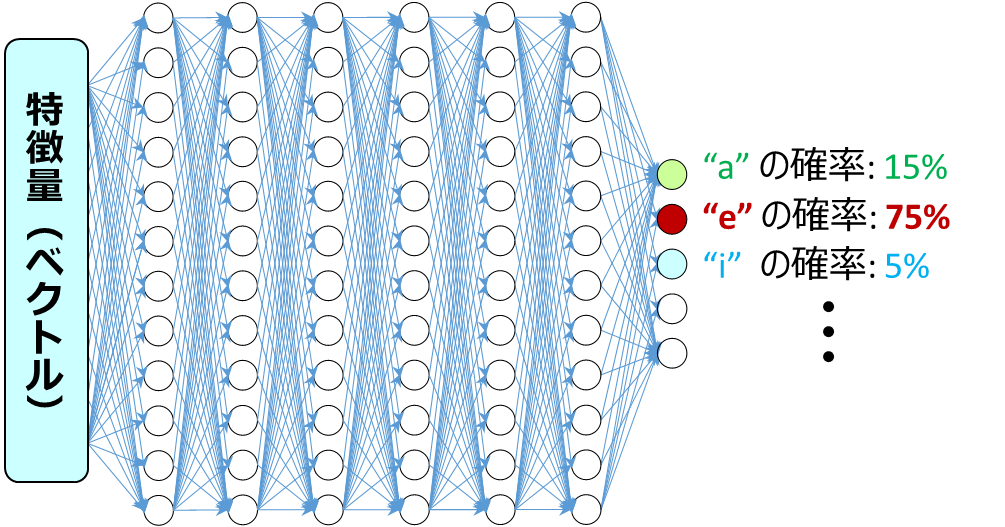
音声認識では、このDNNを「分類器」として利用しています。ハイブリッド型・End-to-End型ともに、入力は音響分析によって得られた音声の特徴量です。DNNはその特徴量がどの音っぽいか(ハイブリッド型では音素単位、End-to-End型では文字や単語単位)を判定し、その確率を出力しています。
ハイブリッド型
上述のDNNと、HMM(Hidden Markov Model, 隠れマルコフモデル)を組み合わせた認識デコーダです。「発音辞書」「音響モデル」「言語モデル」の3つのパーツから構成され、それぞれ以下のような役割があります。HMMの説明も含め、それぞれのパーツがどのように機能するのかは後の「ハイブリッド型の認識デコーダの仕組み」の節で詳しく説明します。
- 発音辞書:それぞれの単語が、どのような音素の並びで表現されるかを定義する
- 音響モデル:入力された特徴量がどの単語の音声に該当する確率が高いかを表す、音響スコアを算出する
- 言語モデル:単語の並びが言語的に自然かどうかを表す、言語スコアを算出する
そして、音響スコアと言語スコアをもとに、最もスコアが高い「単語の並び」を探索して認識結果とする処理をデコードと呼びます。

End-to-End型
近年盛んに研究が行われている新しいタイプの認識デコーダです。以下のイメージのように、ニューラルネットワークに音声特徴量を入力すると、音素ではなく、直接文字や単語が出力されます。文字や単語は音素に比べて種類数が多く、正しく識別するのが難しいタスクでした。近年、ニューラルネットワークの研究や計算機技術が進歩したことで、様々な工夫がされたニューラルネットワークの構築と学習が可能となり、音声認識でも成果をあげつつあります。

ハイブリッド型の図と比べて、認識デコーダの中身がニューラルネットワークだけになっています。ニューラルネットワークが認識結果のテキストを出力するところまで全部やってくれるため構造がシンプルで、発音辞書・音響モデル・言語モデルをそれぞれ用意する必要がないのがメリットの1つです*3。
ハイブリッド型には発音辞書や言語モデルをカスタマイズしやすいというメリットがあるため、現在のところAmiVoiceではハイブリッド型を採用することが多いです。End-to-End型もカスタマイズは可能ですが、ハイブリッド型と比べると手間と時間がかかります。いずれこれらの課題に対応できたら、AmiVoiceの主流もEnd-to-End型になるかもしません。その際にはこのブログで詳しく解説できればと思います!
ハイブリッド型の認識デコーダの仕組み
先ほど、ハイブリッド型の認識デコーダは「発音辞書」「音響モデル」「言語モデル」の3つのパーツから構成されると説明しました。ここからは、それぞれのパーツがどのように機能するのかを詳しく見ていきます。
発音辞書
初めに「発音辞書」から説明します。発音辞書は、「AMI」(弊社の略称です)「秋」「紙」といった単語とその読み、そして "a-m-i"・"a-k-i"・"k-a-m-i" といった音素の表記とを紐づけています。発音辞書により、単語を音素列(音素の並び)で表すことができます。逆に言えば、発音辞書に書かれていない単語は音素列で表すことができないので、認識結果に登場しないということになります。
| 単語 | 読み | 音素表記 |
|---|---|---|
| AMI | あみ | a-m-i |
| 秋 | あき | a-k-i |
| 紙 | かみ | k-a-m-i |
| … | … | … |
音響モデル
音響モデルは、音響分析により得られた特徴量がどの単語の音声に該当する確率が高いかを表す、音響スコアを算出します。「ハイブリッド型認識デコーダ」の説明でも少し触れましたが、ここでDNNとHMMを組み合わせて使っています。それぞれについて見ていきましょう。
HMMとは
音声認識においてHMMは、「単語内での音素の時系列変化」を表現するモデルとして使われます。以下の図を見てください。

いま、「AMI」(読みは「あみ」、音素で書くと"a-m-i")という単語を発話したとします。先ほど音響分析の説明で、「音声波形を細かく区切って切り出す」という話をしました。1フレームは約10ミリ秒(1秒の1/100)単位という非常に短い時間なので、「あみ」と発話すると例えば
「a」の発話に10フレーム→「m」の発話に5フレーム→「i」の発話に15フレーム
のような時間経過をたどることになります。これをHMMで表現すると、
- 1フレーム目に左の黒丸から「a」に移動(黒矢印)
- 2フレーム目から10フレーム目までは「a」に滞在(青矢印)
- 11フレーム目に「a」から「m」へ移動(黒矢印)
- …
のようになります。このように表現することで、発話の速さによる影響を吸収することができます。
音響モデルにおけるDNN
音響モデルでは、音響分析によって得られた音声1フレームの特徴量*4をDNNに入力します。DNNはそのフレームの特徴量がどの音素っぽいかを判定し、その確率を出力します。
DNNとHMMを組み合わせる
DNNとHMMをどのように組み合わせるのか、「あみ」("a-m-i")という単語の発話で説明します。
例えば、DNNの出力が途中のフレームで「"a"の確率が高い状態」から「"m"の確率が高い状態」に変化したら、HMMも「a」から「m」の状態に移動する、というように対応づけることができます。この対応づけを「i」の状態が終了すると推測されるフレームまで行います。すると、それまでにDNNで出力された「各フレームがどの音素っぽいかを示す確率」を使って、「AMI」という単語が発話された確率を計算することができます。この確率をもとに算出された値を、その単語の音響スコアと呼びます。
ただ、音響モデル自身は話者が何と発話しているか、正解を知っているわけではありません。「あき」("a-k-i")、「かみ」("k-a-m-i")など、他にも候補となりそうな単語はあります。こうした単語の音響スコアも計算し、音声認識結果の候補としておきます。
言語モデル
先ほど「発音辞書」の節の例で示した発音辞書には、音素表記が"a-m-i"となる単語は「AMI」だけしかありませんでした。しかし、一般的には「網」や「編み」など、音素表記が"a-m-i"になる単語は複数存在します。これらはどのように区別すればいいのでしょうか。
このような場合に、人間が話し言葉の意味を理解するためにも自然に利用しているのが「文脈」です。例えば、「あみのおんせいにんしき」という文の「あみ」なら「AMI」の可能性が高いですし、「あみでさかなをつかまえる」という文の「あみ」なら「網」の可能性が高いでしょう。ハイブリッド型の認識デコーダでこの「文脈」を判断する役割を果たしているのが言語モデルです。
(日本語の)言語モデルは、単語の並びが日本語としてどのくらい自然か判定し、言語スコアを付けるモデルです。日本語として自然な並びであるほど言語スコアは高くなります。
この言語モデルの「スコア」は、単語の並びが登場する確率から計算されます。

上図は、「走れメロス」の中で「メロス-は」という単語の並びの次に来る単語の確率を示したものです。「走れメロス」のテキストだけで言語モデルを作成した場合、「メロス-は-激怒」という単語の並びの方が「メロス-は-単純」という単語の並びより言語スコアは高くなります。
もちろん、実際の音声認識で使われている言語モデルが「走れメロス」の文章だけで作成されているということはありません。なるべく日本語の表現を網羅するために、議会の議事録やニュース記事など、様々なジャンルのテキストを収集して統計処理し、言語モデルを作成しています。テキストはファイルサイズにして数ギガ~数十ギガバイト、ざっくり換算して「走れメロス(約1万字)」数十万~数百万作分という膨大な量を使用しています。
デコードと仮説
「発音辞書」「音響モデル」「言語モデル」から得られた音響スコアと言語スコアをもとに、最もスコアが高い「単語の並び」を探索して認識結果とする処理をデコードと呼びます。このデコードの処理の概要を説明します。
今、とある日本語音声を認識しようとしていると思ってください。
仮説とは、その音声の内容となりうる全ての日本語の文章のことです。そして、それらが音声認識結果の候補となります。
現在の季節は夏ではないかもしれませんが、例えば私が「暑中お見舞い申し上げます」と言ったとしましょう。当然、"暑中お見舞い申し上げます" も仮説の一つですが、同時に "こんばんは" や "板垣死すとも自由は死せず" なども仮説になりえます。よりまともな仮説だと、 "焼酎を振る舞い申し上げます" や "書中を見舞いも牛上げます" などがあるでしょうか。日本語の単語数を仮に10万と考えれば、10単語の文章に限っても、10万^10 = 1050 もの仮説があります。
理想的な音声認識では、こういった仮説たちのすべてについて、単語ごとの音響スコアと言語スコアを加算し、各仮説のスコア、すなわち音声「暑中お見舞い申し上げます」と合致する確率を計算します。そして、最もスコアの高い仮説を認識結果とします。
先ほどの仮説のスコアは、以下の表のようになるはずです。
| 仮説 | 音響スコア | 言語スコア | 理由 |
|---|---|---|---|
| "焼酎を振る舞い申し上げます" | 低い | 高い | 音声と合致していないが、日本語としては自然な文である |
| "書中を見舞いも牛上げます" | 高い | 低い | 音声は合致しているが、日本語として自然な文ではない |
| "暑中お見舞い申し上げます" | 高い | 高い | 音声は合致しているし、日本語として自然な文である |
なお、現実には 1050 個全ての仮説を採点することはありません。途中までのスコアが(相対的に)とても悪い仮説は、最後の方までスコアを計算しても、全体のスコアで他の仮説に負けてしまう可能性が高いからです。このように、絶望的な仮説 "板垣…" を予選敗退で済ませることを枝刈りといいます。デコードではこの枝刈りを適切に行うことで、現実的な処理時間で認識結果を出すことを可能にしています。
より精度の高い音声認識のために~適切なエンジンを選ぶ~
精度の高い音声認識結果を得るために重要なのは、発話の音声や内容になるべくフィットした音響モデルや言語モデル*5を利用することです。例えば、会議の音声をマイクで録音するのと、コールセンターの通話をヘッドセットで録音するのでは、音質や録音環境が大きく異なります。また、お医者さんの診察室での発話内容と議員さんの議会での発話内容では、登場する単語の種類から頻度まで大きく異なります。このため、AmiVoiceでは複数の音響モデル・言語モデルを作成し、これらを組み合わせて提供しています。
AmiVoiceでは、この音響モデルと言語モデルの組をエンジン*6と呼んでいます。AmiVoiceの製品やAPIではエンジンを選択できるものも多くあります。例えば、AmiVoice APIでは「汎用_会話」「医療_音声入力」など、下記のエンジンを提供しています。
また、お客様のご要望に合わせ、音響モデルや言語モデルをカスタマイズしたエンジンも提供しています。適切なエンジンを使うことが、AmiVoiceの威力を最大限に発揮するキーポイントになるので、ぜひあなたに合ったエンジンを使ってみてください!
おわりに
今回の記事では、ざっくりと「音声認識の仕組み」を解説しました。この分量で「『ざっくり』なの!?」と驚かれる方もいるかもしれません(執筆した私も驚いています)。「音声をテキストにする」という人間には当たり前のようにできることが、コンピュータ上では様々な技術を組み合わせてようやく実現できます。その奥深さと面白さが少しでも伝わっていればいいなと思います。
もしこの記事を見て音声認識技術やAmiVoice APIに興味を持った開発者の方がいましたら、ぜひ https://acp.amivoice.com/amivoice_api/ を試してみてください。毎月音声60分までは全エンジン無料で使えます。
ここまでお読みいただき、ありがとうございました!
謝辞
この記事を執筆するにあたり、先輩の木曽義某さんにアドバイスいただきました。感謝申し上げます。
この記事を書いた人
-
大倉尭
新卒でアドバンスト・メディアに入社。
現在の仕事は音声認識の精度向上のための研究開発がメインです。
趣味は旅行(主に鉄道)・読書(主に小説)・ボードゲームなど。
*1:音声の録音や、波形およびスペクトログラムの表示にはAudacity ( https://www.audacityteam.org/ ) というオープンソースのツールを使用しました。
*2:縦軸の数字をよく見ると分かるのですが、周波数の低い(音が低い)部分は間隔が広く、周波数の高い(音が高い)部分は間隔が狭くなっています。これは、低い音は周波数の違いに敏感な一方、高い音では周波数の違いに鈍感である人間の聴覚の特性に基づいたもので、メル尺度と呼ばれます。音声波形を特徴量にする際もこのメル尺度を考慮することが多いので、可視化の図ではメル尺度を採用しました。
*3:言語モデルを組み合わせることは可能で、これにより認識精度が上がるという研究もあります。
*4:該当するフレームの前後の情報を使うために、数フレーム~数十フレーム分の特徴量をまとめて入力する場合もあります。
*5:発音辞書は言語モデルに応じて決まることが多いため、この2つをまとめて「言語モデル」と呼ぶ場合もあります。
*6:弊社の商品によっては、「エンジンモード」や「マスター辞書」など異なる表現が使われている場合があります。